Qué es Machine Learning (ML) o Aprendizaje Automático
Machine Learning es un subcampo de la inteligencia artificial que hace posible que los ordenadores puedan aprender de forma automática, es decir, sin intervención humana más allá de la programación inicial de los algoritmos de aprendizaje automático.
Dentro de la ciencia de datos conocida como Machine Learning existen diversos algoritmos y, en este artículo vamos a describir los más utilizados y eficientes al usar Machine Learning con Python.
Índice de Machine Learning:
Introducción a Machine Learning o Aprendizaje Automático
En informática existen diferentes ramas o subcampos de las ciencias de la computación y, una de ellas es la inteligencia artificial, cuyo objetivo es crear técnicas para permitir que los ordenadores aprendan. Para ello hay que suministrarles conjuntos de datos y, mediante Python, una de las técnicas utilizadas es hacerlo con datasets o con DataFrames pandas junto con la visualización de datos con Matplotlib y Seaborn, aunque es posible utilizar otros conjuntos de datos usando bibliotecas de código Python diferentes a pandas, como por ejemplo Scikit-Learn, SciPy, Keras Tensorflow y muchas otras. Sin embargo, las indicadas son las librerías más comunes para alimentar los algoritmos de machine learning siempre que nos refiramos al lenguaje de programación Python. En cualquier caso, la inteligencia artificial siempre necesitará datos en los que basarse, bien sean estos matemáticos y científicos en formato numérico, culturales y gramaticales en formato de texto, etc., para su posterior procesamiento matemático.
Machine Learning, como ya habrás descubierto, también recibe también el nombre de aprendizaje automático, que no es más que el proceso en el que un ordenador aprende observando los datos. Si bien hemos comentado que estos, los datos son procesados matemáticamente, para aprender a programar ML no es necesario conocer profundamente las matemáticas. ¡Eso que ganamos!
Para que ML pueda funcionar, como hemos mencionado, es necesario desarrollar algoritmos de aprendizaje, a los que debemos suministrar datos, es decir, primeramente crear un modelo con algoritmos de machine learning y posteriormente alimentar el modelo con los datos deseados para que, de una forma transparente el programa pueda aprender y realizar hipótesis sobre el conjunto de datos suministrado.
Objetivo de Machine Learning
El principal objetivo del aprendizaje automático o machine learning es aprender sobre el mundo, realizar hipótesis y solucionar problemas de una forma sencilla y práctica, reduciendo la carga de trabajo de los humanos. Su gran avance es debido a la actual velocidad con la que crece la tecnología, haciendo difícil para una persona corriente poder tratar con los grandes volúmenes de datos que se generan cada día. De esta forma, podemos encontrar multitud de tareas y trabajos en los que ML nos puede ayudar.
Los objetivos principales de machine Learning son los siguientes:
Realizar estadísticas, cálculos matemáticos complejos, elaborar hipótesis con ciencias de datos, etc.
Descubrimiento y reconocimiento de patrones.
Motores de búsqueda de internet.
Diagnósticos médicos.
Detección de fraudes con tarjetas de crédito.
Análisis de mercados y operaciones bursátiles.
Estudio y clasificación de secuencias de ADN.
Generación de texto automático.
Reconocimiento facial.
Reconocimiento del habla.
Robótica.
Geolocalización, mapas complejos.
Detección de spam, bots en redes sociales y en internet en general.
Creación de juegos que se actualizan en tiempo real según el usuario y tipo de partida.
Al construir un modelo basado en los datos se utiliza ese modelo para crear una hipótesis o supuesto sobre el mundo mediante el software creado, dando como resultado la resolución de problemas complejos.
El aprendizaje automático tiene muchas aplicaciones en la actualidad y, a medida que avanza la interconexión mediante internet salen muchos más usos para ML.
Otras ramas de la Inteligencia Artificial
Asimismo, dentro de la inteligencia artificial también podemos encontrar otros tipos de ramas o ciencias como:
Deep Learning.
Big Data.
Data Science.
Deep Learning
Deep Learning es la rama de la inteligencia artificial que se encarga del aprendizaje profundo, es decir, simular el proceso de aprendizaje de las máquinas mediante redes neuronales artificiales.
Las diferencias entre Machine Learning y Deep Learning son en que ML se encarga del aprendizaje superficial mientras que, DL pasa al aprendizaje profundo para simular el funcionamiento del cerebro humano, tratando de imitar las conexiones neuronales del cerebro y eléctricas de las células del cuerpo humano. Deep Learning es un mecanismo de aprendizaje por capas, y de ahí lo de "profundo". Va desde los problemas más sencillos a los más complejos, desde las capas más superficiales a las más profundas, de problemas simples y concreto a problemas abstractos.
Big Data
El Big Data es la rama o ciencia de la Inteligencia Artificial que se encarga de procesar y aprender de grandes volúmenes de datos, generalmente obteniendo gigas y terabytes de ellos.
Dentro de Big Data podemos encontrar las 3V´s o las 3´s (velocidad, variedad y velocidad):
Volumen: es la cantidad de información con la que se trabaja.
Variedad: son los tipos de datos suministrados u obtenidos por los algoritmos, pudiendo ser conjuntos de datos estructurados y no estructurados.
Velocidad: es la rapidez con la que se obtienen los datos. Pueden actualizarse por horas, días, meses, etc.
Como en Big Data se trata una enorme cantidad de datos, la obtención de los mismos variará según el trabajo realizado y los objetivos, generalmente programando su obtención mediante código para obtener los conjuntos de datos de forma automática o en modo batch. Por ejemplo, todas las interacciones que tenemos en redes sociales como Twitter, Facebook, Instagram e incluso la forma de interactuar con buscadores como Google son guardadas y analizadas de forma automática.
Data Science
La denominada Ciencia de Datos o Data Science se desarrolla en cuatro áreas principales:
Matemática y estadística.
Programación.
Negocios.
Aprendizaje y comunicación.
Los científicos de datos o Data Scientists se encargan, generalmente, de la obtención y tratamiento de datos para aportar valor a los modelos de Machine Learning, diferenciándose del Big Data en que los conjuntos de datos son relativamente más pequeños. Sin embargo, todas las ramas de IA interactúan entre ellas, haciendo difícil diferenciar, en la mayoría de los casos cuando es una u otra cuando se desarrollan en entornos profesionales y laborales.
Similitudes entre Machine Learning e Inteligencia Artificial
Como ya hemos expuesto, en una gran variedad de trabajos y desarrollos, las ramas de la inteligencia artificial se solapan, produciendo que los científicos de datos realicen muchos tipos de tareas relacionadas que, si bien en un principio son parte de otra rama o departamento, al final son necesarias para llevar a cabo el objetivo fijado.
Machine Learning incorpora en sus algoritmos partes de inteligencia artificial, ciencias de la computación y neurociencia, haciendo un amalgama del saber humano para resolver problemas complejos.
Tipos de algoritmos de Machine Learning
Dada la extensión y diversos usos y aplicaciones de ML, como es natural, podemos encontrar diferentes tipos de algoritmos de Machine Learning:
Los algoritmos de Machine Learning supervisado aprenden de datos etiquetados. El volumen de datos proporcionado tiene las soluciones deseadas para que la máquina pueda evaluar las preguntas y soluciones y, a partir de ahí, poder resolver futuras cuestiones y problemas, siempre basándose en los datos suministrados inicialmente.
El conjunto de datos contiene etiquetas para cada dato: etiqueta o label. El modelo necesita la identificación de los datos para construir respuestas correctas.
El funcionamiento del aprendizaje supervisado se basa en:
Programación de los algoritmos supervisados.
Obtención de los datos etiquetados de entrada.
Entrenamiento del modelo con el conjunto de datos.
Realización de predicciones y suministro de datos de salida.
Los algoritmos de Machine Learning no supervisado tienen la finalidad de aprender de datos no etiquetados. Su funcionamiento se basa en la obtención de relaciones internas entre los datos sin que estos tengan las soluciones, es decir, las máquinas aprenderán patrones no existentes previamente.
La intervención humana en ML no supervisado está centrada en los objetivos que se desean alcanzar, proporcionando la programación de los algoritmos.
Machine Learning no supervisado se divide, a su vez, en dos grandes ramas o técnicas:
Clustering: agrupación de datos mediante similitud para identificar diferentes subconjuntos de datos dentro del conjunto de datos principal. Por ejemplo: identificar distintos grupos de clientes en base a su facturación u otros parámetros.
Asociación: detección de relaciones ocultas en los datos obtenidos o suministrados. Por ejemplo: para realizar predicciones de productos que pueden interesar a un cliente.
Aprendizaje semisupervisado
El aprendizaje semi-supervisado es un tipo de aprendizaje automático en el cual el algoritmo se entrena en un conjunto de datos que incluye tanto datos etiquetados como no etiquetados. El objetivo es aprovechar los datos no etiquetados junto con los datos etiquetados para mejorar el rendimiento del modelo. Esto puede ser útil en situaciones en las que obtener datos etiquetados es difícil o costoso, ya que permite al modelo utilizar información adicional para mejorar su rendimiento sin tener la necesidad de etiquetar todos los datos.
El aprendizaje semi-supervisado es un punto medio entre el aprendizaje supervisado y el no supervisado. El aprendizaje supervisado requiere datos etiquetados para entrenar el modelo, el no supervisado solo usa datos no etiquetados y no usa datos etiquetados, pero el aprendizaje semi-supervisado utiliza una combinación de ambos datos etiquetados y no etiquetados.
Aprendizaje on-line
El aprendizaje on-line, también conocido como aprendizaje incremental, es un tipo de aprendizaje automático en el que el modelo se entrena de manera incremental con los datos que entran, en lugar de usar todos los datos a la vez. Esto permite al modelo adaptarse a la nueva información y mejorar su rendimiento con el tiempo.
El aprendizaje on-line es especialmente útil cuando se trabaja con grandes conjuntos de datos, con datos en streaming o datos online, ya que permite al modelo aprender en tiempo real sin necesidad de almacenar todos los datos en la memoria o en soportes físicos del servidor. Tiene la ventaja de poder actualizar el modelo con nuevos datos a medida que están disponibles, lo que significa que puede mejorar con el tiempo y seguir adaptándose mientras está en funcionamiento.
Además, el aprendizaje on-line es una buena opción cuando la tarea requerida es un proceso continuo, donde no se trata de una predicción única sino de un monitoreo constante, esto permite que el modelo se adapte con nuevos datos y mejore con el tiempo, a diferencia de los otros tipos de aprendizaje no on-line donde el modelo se entrena con un conjunto de datos fijo y no puede mejorar con el tiempo, solo puede hacer predicciones utilizando ese conjunto de datos fijo, salvo que sean suministrados nuevos datos reiniciando el modelo. Algo que suele requerir bastante tiempo si el tamaño de los datos es extenso ya que, el entrenamiento del modelo de datos es lo más lento de todo el proceso como comprobarás si aprendes Machine Learning con nuestros tutoriales.
Aprendizaje por refuerzo
El aprendizaje por refuerzo (RL) es un tipo de aprendizaje automático en el que el programa o máquina aprende a tomar decisiones a través de la interacción con el entorno, recibiendo retroalimentación en forma de recompensas o penalizaciones. El objetivo es que el programa aprenda de forma automática para maximizar las recompensas a lo largo del tiempo. Este tipo de Machine Learning aprende del feedback o retroalimentación por interacción.
En RL, la máquina aprende a través de ensayo y error, tomando acciones y observando los aciertos y fallos resultantes. Utiliza esta retroalimentación para actualizar su comprensión del entorno y mejorar sus decisiones a largo plazo.
El aprendizaje por refuerzo se utiliza en una amplia variedad de aplicaciones, como la robótica, los juegos y la toma de decisiones en sistemas complejos. También se ha utilizado en campos como las finanzas y la gestión de la energía.
El aprendizaje por refuerzo es diferente al aprendizaje supervisado, ya que no utiliza datos etiquetados, en su lugar utiliza las recompensas o penalizaciones como retroalimentación. En este sentido, es más similar al aprendizaje no supervisado, pero en el aprendizaje no supervisado el software no tiene un objetivo que alcanzar, mientras que en el RL el software tiene un objetivo que alcanzar.
Aprendizaje automático generativo
El aprendizaje automático generativo es un tipo de aprendizaje automático que tiene como objetivo generar nuevos datos que se parezcan a los datos de entrenamiento. El modelo aprende a generar nuevos datos a partir de la distribución de los datos de entrenamiento. Los algoritmos de aprendizaje automático generativo son una forma de aprendizaje automático no supervisado, ya que no se proporciona una etiqueta o salida esperada.
Diferencia entre aprendizaje automático supervisado y no supervisado
La principal diferencia entre el aprendizaje automático supervisado y no supervisado es la presencia o ausencia de etiquetas en los datos de entrenamiento (labels).
En el aprendizaje automático supervisado, se tiene acceso a datos de entrada-salida (también conocidos como etiquetas) durante el proceso de entrenamiento. El algoritmo de aprendizaje automático "aprende" a inferir la salida deseada a partir de una entrada dada, a través de la comparación entre las salidas pronosticadas y las salidas reales. Los ejemplos más comunes de tareas supervisadas son clasificación y regresión. En el aprendizaje automático no supervisado, no se proporcionan pares de entrada-salida durante el proceso de entrenamiento. El conjunto de datos carece de etiquetas. En su lugar, el algoritmo de aprendizaje automático busca patrones y estructuras en los datos de entrada para ser capaz de producir salida de datos correctas sin recibir previamente los etiquetados. Los ejemplos de tareas no supervisadas son la agrupación (clustering) y la reducción de dimensionalidad.
Ejemplos de Machine Learning
Ejemplos de aprendizaje automático supervisado
Uno de los ejemplos habituales y más claros para aprender qué es el aprendizaje supervisado es pensar en un programa de detección de correos electrónicos de spam.
Ejemplo de aprendizaje automático supervisado, regresión lineal simple con visualización de datos mglearn y Python.
Inicialmente, durante la fase de entrenamiento al sistema se le proporciona un conjunto de e-mails clasificados (etiquetados) para que el modelo pueda conocer de antemano las similitudes y diferencias de los correos electrónicos buenos y malos, es decir, los emails deseados y los no deseados. Durante el entrenamiento, la máquina encontrará patrones y similitudes entre las diferentes categorías de etiquetas de forma automática.
En la fase final del aprendizaje supervisado, el modelo será capaz de predecir cuando llega un nuevo email, si pertenece a la categoría de spam o correo deseado y realizar las operaciones indicadas en base a su programación. Por ejemplo, llevar el email a la carpeta de spam, carpeta de correo no deseado o directamente eliminarlo del sistema. ¿Te suena cómo puede funcionar el famoso correo de Gmail? ¡Eso es! ¡Con Machine Learning!
Ejemplos de aprendizaje no supervisado
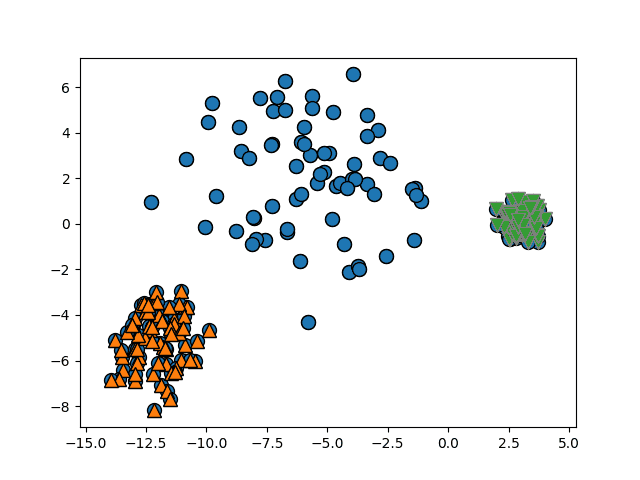
Un ejemplo de aprendizaje no supervisado es el agrupamiento de datos, también conocido como clustering. El agrupamiento es una técnica utilizada para agrupar puntos de datos similares en conjuntos o clústeres. El algoritmo se entrena en un conjunto de datos no etiquetado, y busca encontrar patrones y relaciones en los datos que se puedan utilizar para agrupar puntos de datos similares juntos.
Ejemplo de agrupamiento de datos (clustering) con Machine Learning o aprendizaje automático no supervisado visualizado con Matplotlib y Python.Un ejemplo de agrupamiento podría ser agrupar los datos de los clientes por su comportamiento de compra. Dado un conjunto de transacciones de clientes, un algoritmo de agrupamiento se puede entrenar para agrupar a los clientes en base a los productos que compran, con qué frecuencia realizan una compra y cuánto gastan. Esto puede ser útil para una tienda minorista para identificar diferentes segmentos de clientes y adaptar sus campañas de marketing a cada segmento.
Otro ejemplo es la detección de anomalías, una técnica utilizada para identificar puntos de datos inusuales o anormales en un conjunto de datos. La detección de anomalías es útil en una amplia variedad de aplicaciones, como la detección de fraude, la detección de intrusiones en redes y el control de calidad en la fabricación de productos. En este caso, el algoritmo no conoce de antemano los patrones que debería encontrar, solo utiliza el conjunto de datos para encontrar patrones y clasificar los puntos de datos como normales o anormales, es responsabilidad del experto en el dominio decidir si los patrones detectados son útiles o no.
 En cualquier caso, la inteligencia artificial siempre necesitará datos en los que basarse, bien sean estos matemáticos y científicos en formato numérico, culturales y gramaticales en formato de texto, etc., para su posterior procesamiento matemático.
En cualquier caso, la inteligencia artificial siempre necesitará datos en los que basarse, bien sean estos matemáticos y científicos en formato numérico, culturales y gramaticales en formato de texto, etc., para su posterior procesamiento matemático.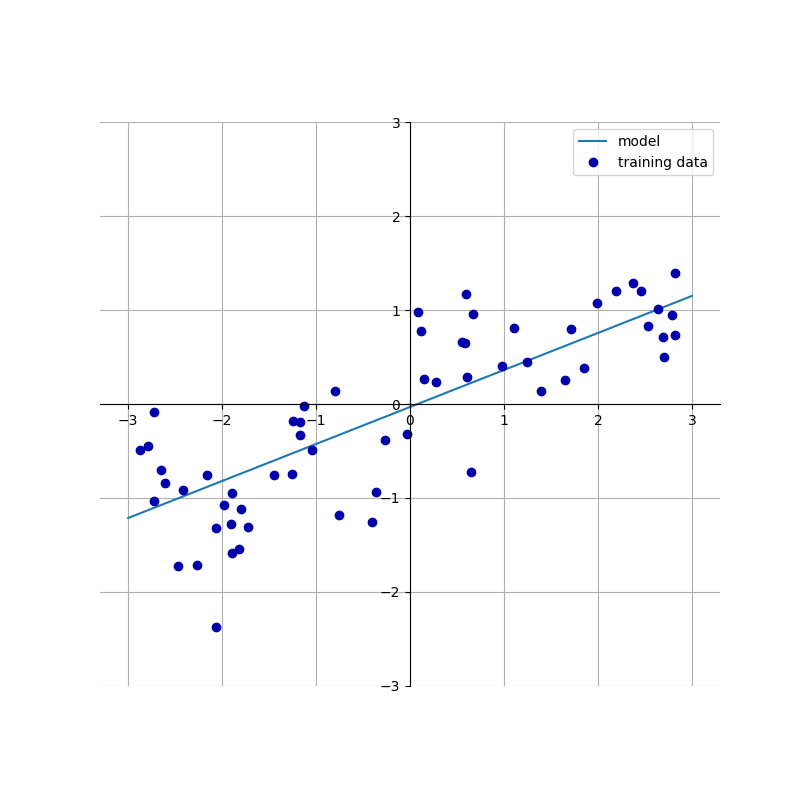
Comentarios del artículo "Qué es Machine Learning (ML) o Aprendizaje Automático"
¿Te ha gustado la información? Coméntanos tus opiniones, dudas y sugerencias: