Cómo crear un mapa de calor de correlaciones de datos en Python (corrcoef y heatmap)
Para crear un mapa de calor de correlaciones en Python vamos a utilizar el método corrcoef de Numpy y el método heatmap de la biblioteca Seaborn. Estas dos funciones nos permitirán generar una imagen con los valores de las relaciones de cada columna contenidas dentro del conjunto de datos que trabajamos, así como establecer visualmente diferentes colores para representar la correlación de variables. Esta forma de procesar las relaciones de datos tiene similitudes con otros que ya hemos usado como el descubrimiento de correlaciones con pandas corr y crear una imagen de correlaciones con pairplot.
Como vas a comprobar, mediante heatmap crearemos el gráfico, pasándole como parámetros la matriz de correlaciones generada con corrcoef. Para ello, necesitaremos importar las biblioteca de código Python numpy.corrcoef y seaborn.heatmap que voy a ir explicando.
El coeficiente de correlación es un número entre -1 y 1 que indica la relación lineal entre dos variables. Un valor cercano a 1 indica una correlación positiva fuerte, un valor cercano a -1 indica una correlación negativa fuerte y un valor cercano a 0 indica una falta de correlación. Un valor positivo indica que el aumento del valor de la primera variable provoca que la segunda aumente también su valor y, un resultado negativo indica que el aumento del valor hará que baje el segundo. Los resultados cercanos a cero informan que no hay relación y, por tanto, no hay influencia entre esas columnas o variables.
Valores de los coeficientes de correlación corrcoef:
Para usar corrcoef de NumPy, solo hay que escribir lo siguiente:
Los mapas de calor (heatmap) son útiles para visualizar patrones y tendencias en datos multivariados, especialmente cuando hay muchos datos y se busca una representación resumida y, dentro de estos patrones, heatmap es perfecto para visualizar las correlaciones de columnas de un dataframe que previamente hemos podido cargar con datos procedentes de un archivo .csv o .xlsx de Excel.
En el código primero realizamos las importaciones de las bibliotecas de Python que vas a usar.
Seguidamente, cargamos los datos. En esta ocasión he optado por seguir el mismo ejemplo que con la obtención de correlaciones con corr de la biblioteca pandas y con el método pairplot de seaborn. De esta forma, tenemos el mismo conjunto de datos pero diferente forma de obtener las correlaciones para poder comparar los resultados entre las diversas formas de encontrar relaciones entre columnas que componen nuestro conjunto de datos.
La tercera línea de código es el cálculo de la matriz de correlación. Para ello solo tenemos que usar 'numpy.corrcoef' que puedes ver en el ejemplo como corr = np.corrcoef(data.T). Indica que, para el conjunto de datos 'data' calcule las relaciones.
Lo último es crear el mapa de calor que lo hacemos con 'sns.heatmap', pasándole como parámetro los valores obtenidos con corrcoef que hemos almacenado en la variable llamada corr, los valores para el eje x con xticklabels y los valores para el eje y con yticklabes.
El resultado es el siguiente:
En la imagen generada con heatmap están dispuestas las columnas del conjunto de datos, cada una de ellas con una escala de color en función del grado de correlación con la otra columna. A la derecha vemos la escala de valores que indica el grado de correlación desde -1 a 1.
Ahora bien, el código es bastante sencillo, pero podemos mejorarlo mostrando en cada celda el valor de la correlación correspondiente.
Modificamos el script anterior con las correlaciones en Python solo cambiando la línea de código donde se genera la imagen:
La opción 'annot=True' permite mostrar los valores de correlación en cada celda del mapa de calor y 'fmt='.2f'' indica que solo se mostraran 2 decimales en las correlaciones. El código es similar al anterior, pero con estas opciones adicionales se mostrará en cada cuadro del mapa de calor la correlación correspondiente. Solo hay que modificar la línea 'sns.heatmap', añadiendo 'annot' y 'fmt'.
Y tenemos el resultado siguiente:
En esta representación gráfica de las correlaciones ya no es necesario acudir a la línea lateral para verificar el valor de cada una de ellas sino que, en su lugar, tenemos el valor de la correlación impreso en cada celda. En mi opinión es mucho más sencillo y claro de entender. Sin embargo, al mostrar todas las variables en el mapa de calor, los coeficientes de correlación se muestran algo apelotonados, quizás demasiado juntos para una lectura amigable.
¿Te atreves a probar otras opciones para una mejor visualización del mapa de calor?
Y tendríamos el resultado siguiente:
En este ejemplo último, hemos desactivado a barra lateral con la escala de colores agregando 'cbar=False', establecer que los ejes sean iguales con 'square=True', modificar el tamaño de la fuente de los valores de correlación en las celdas con 'annot_kws= 7' y añadido espacio de separación entre celdas 'linewidth=.5'.
Con pequeñas modificaciones en el mapa de calor podemos mejorar mucho su legibilidad.
También podemos asignar el tamaño de la fuente a las etiquetas, en este caso indicando 'font_scale=1.5', pero dándole su tamaño antes de generar la imagen de la siguiente forma:
Y da como resultado lo siguiente: 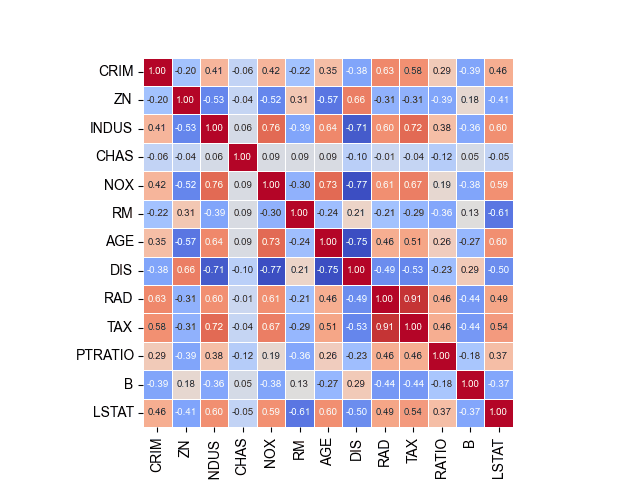 Y conseguiríamos el siguiente resultado:
Y conseguiríamos el siguiente resultado:

La diferencia en este ejemplo es el uso de pandas en lugar de solo utilizar una matriz NumPy. El uso de un DataFrame pandas facilita mucho el trabajo y reduce la complejidad a la hora de modificar y añadir columnas ya que con NumPy en muchas ocasiones es una tarea compleja, al menos mucho más que la facilidad que proporciona pandas.
El dataset lo asignamos a un DataFrame pandas, además, también añadimos una nueva columna llamada 'MEDV' como hicimos en los otros ejemplos de correlación de variables que hemos mencionado y enlazado, los ejemplos para descubrir relaciones con el método corr() de pandas y mostrarlas gráficamente con pairplot() de seaborn.
Asimismo, indicamos los nombres de las columnas en la variable llamada 'columnas' que vamos a obtener y que también nos sirve para añadir esos nombres en la cabecera del DataFrame y usarlo como índice cuando convertimos la matriz NumPy a un DataFrame pandas.
El cálculo del coeficiente de correlación lo realizamos de la misma forma, con el método numpy.corrcoef.
La generación del gráfico es igual, solo añadiendo el título, que es algo que en los otros ejemplos no habíamos añadido. El título lo añadimos con plt.title('Diagrama de correlación', color='#E9785D'), que es tono naranja.
Y para finalizar, también exportamos los datos a un archivo csv para poder disponer de ellos cuando los necesitemos.
Con esto, ya tendríamos 3 formas de mostrar las correlaciones en Python para poder analizar datos y usarlos de forma eficaz en nuestros modelos de Machine Learning y desarrollos de aprendizaje automático supervisado para hacer una mejor minería de datos de clientes y ofrecer una visión más completa de múltiples cuestiones sobre la evolución del negocio y posibles oportunidades que, a simple vista pueden resultar difíciles de encontrar.
Como vas a comprobar, mediante heatmap crearemos el gráfico, pasándole como parámetros la matriz de correlaciones generada con corrcoef. Para ello, necesitaremos importar las biblioteca de código Python numpy.corrcoef y seaborn.heatmap que voy a ir explicando.
- Índice Mapa de calor de correlaciones en Python:
Cómo usar corrcoef de NumPy
El método 'corrcoef' en Python es una función de la biblioteca estadística NumPy que se utiliza para calcular la matriz de correlación entre dos o más variables. La matriz de correlación es una tabla que contiene los coeficientes de correlación entre todas las posibles parejas de variables en un conjunto de datos. Es decir, las relaciones que existen entre las distintas columnas de datos con las que trabajamos.El coeficiente de correlación es un número entre -1 y 1 que indica la relación lineal entre dos variables. Un valor cercano a 1 indica una correlación positiva fuerte, un valor cercano a -1 indica una correlación negativa fuerte y un valor cercano a 0 indica una falta de correlación. Un valor positivo indica que el aumento del valor de la primera variable provoca que la segunda aumente también su valor y, un resultado negativo indica que el aumento del valor hará que baje el segundo. Los resultados cercanos a cero informan que no hay relación y, por tanto, no hay influencia entre esas columnas o variables.
Valores de los coeficientes de correlación corrcoef:
- 1 = correlación positiva fuerte.
- -1 = correlación negativa fuerte.
- 0 = falta de correlación
- Valores soportados por el coeficiente de correlación: entre -1 y 1.
# Calcula la matriz de correlación
corr = np.corrcoef(data.T)
Cómo usar heatmap de Seaborn
Un heatmap o mapa de calor es un tipo de gráfico que se utiliza para representar información en una matriz, donde cada celda de la matriz se colorea según un valor escalar. En Python, se puede crear un heatmap utilizando la biblioteca de visualización de datos 'seaborn'. La función 'heatmap' de seaborn permite crear un heatmap a partir de una matriz de datos y colorear las celdas según un mapa de colores específico. Además de los datos, se pueden especificar opciones adicionales como el rango de los valores a representar, el tamaño del gráfico y las etiquetas del eje x e y.Los mapas de calor (heatmap) son útiles para visualizar patrones y tendencias en datos multivariados, especialmente cuando hay muchos datos y se busca una representación resumida y, dentro de estos patrones, heatmap es perfecto para visualizar las correlaciones de columnas de un dataframe que previamente hemos podido cargar con datos procedentes de un archivo .csv o .xlsx de Excel.
# Crear heatmap
sns.set(font_scale=1.5)
sns.heatmap(
corr, xticklabels=nombre_etiquetas_ejeX, yticklabels=nombre_etiquetas_ejeY, cmap='coolwarm', annot=True, fmt='.2f',
cbar=False,
square=True,
annot_kws={'size': 7},
linewidth=.5,
)
# Muestra el gráfico
plt.show()
A continuación, vamos a ver un ejemplo de cómo crear un mapa de calor calculando las correlaciones del conjunto de datos y creando una imagen con los datos resultantes.
Obtener las correlaciones de datos con corrcoef y heatmap
Vamos a crear el script de correlaciones de datos en Python. Este tiene una extensión pequeña y muestro a continuación cómo es:
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.datasets import load_boston
# Carga el dataset Boston
boston = load_boston()
# Obtiene los datos de las variables
data = boston.data
# Calcula la matriz de correlación
corr = np.corrcoef(data.T)
# Crear heatmap
sns.heatmap(corr, xticklabels=boston.feature_names, yticklabels=boston.feature_names, cmap='coolwarm')
# Muestra el gráfico
plt.show()
Seguidamente, cargamos los datos. En esta ocasión he optado por seguir el mismo ejemplo que con la obtención de correlaciones con corr de la biblioteca pandas y con el método pairplot de seaborn. De esta forma, tenemos el mismo conjunto de datos pero diferente forma de obtener las correlaciones para poder comparar los resultados entre las diversas formas de encontrar relaciones entre columnas que componen nuestro conjunto de datos.
La tercera línea de código es el cálculo de la matriz de correlación. Para ello solo tenemos que usar 'numpy.corrcoef' que puedes ver en el ejemplo como corr = np.corrcoef(data.T). Indica que, para el conjunto de datos 'data' calcule las relaciones.
Lo último es crear el mapa de calor que lo hacemos con 'sns.heatmap', pasándole como parámetro los valores obtenidos con corrcoef que hemos almacenado en la variable llamada corr, los valores para el eje x con xticklabels y los valores para el eje y con yticklabes.
El resultado es el siguiente:
En la imagen generada con heatmap están dispuestas las columnas del conjunto de datos, cada una de ellas con una escala de color en función del grado de correlación con la otra columna. A la derecha vemos la escala de valores que indica el grado de correlación desde -1 a 1.
Ahora bien, el código es bastante sencillo, pero podemos mejorarlo mostrando en cada celda el valor de la correlación correspondiente.
Añadir valor de correlación al mapa de calor
Para poder visualizar de forma gráfica el valor de la correlación de cada variable en el cuadro de color en el mapa de calor usaremos 'annot' y 'fmt' de seaborn:Modificamos el script anterior con las correlaciones en Python solo cambiando la línea de código donde se genera la imagen:
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.datasets import load_boston
# Carga el dataset Boston
boston = load_boston()
# Obtiene los datos de las variables
data = boston.data
# Calcula la matriz de correlación
corr = np.corrcoef(data.T)
# Crear heatmap
sns.heatmap(corr, xticklabels=boston.feature_names, yticklabels=boston.feature_names, cmap='coolwarm', annot=True, fmt='.2f')
# Muestra el gráfico
plt.show()
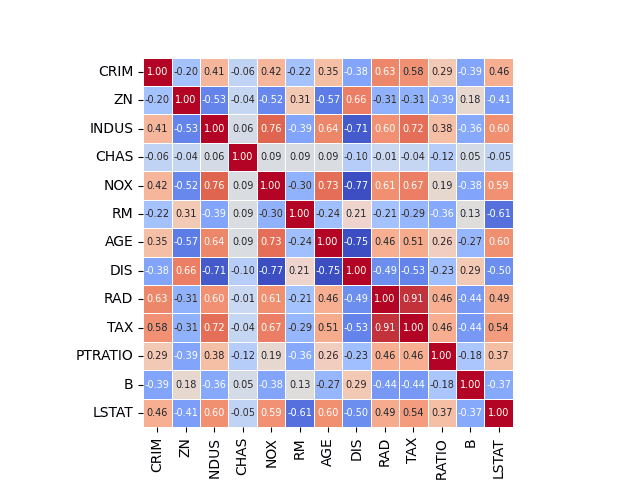
Y tenemos el resultado siguiente:
En esta representación gráfica de las correlaciones ya no es necesario acudir a la línea lateral para verificar el valor de cada una de ellas sino que, en su lugar, tenemos el valor de la correlación impreso en cada celda. En mi opinión es mucho más sencillo y claro de entender. Sin embargo, al mostrar todas las variables en el mapa de calor, los coeficientes de correlación se muestran algo apelotonados, quizás demasiado juntos para una lectura amigable.
Opciones del mapa de calor heatmap
- cbar: True o False. Muestra la barra lateral con el esquema de colores y valores de la correlación.
- square: True o False.
- True: establece el aspecto de los ejes iguales para que cada celda del mapa de calor tenga forma cuadrada.
- annot_kws: tamaño de la fuente. Podemos ajustar el tamaño de los valores de las correlaciones mostrados en cada celda.
- linewidth: separación entre celdas.
- cmap: paleta de colores a usar. En el ejemplo usamos 'coolwarm', pero hay muchos más como 'Set2', 'YlGnBu', 'Blues', 'BuPu', 'Greens', etc. Puede modificarse a nuestro antojo siguiendo las indicaciones de elegir paleta de colores y control del color en los mapas de calor.
- Otras opciones disponibles: consultar documentación oficial seaborn heatmap.
Mapa de calor con opciones incluidas
Vamos a probar cómo se vería el mapa de calor incluyendo algunas de las opciones descritas. Para ello, modifica la línea de código en donde creamos la imagen 'sns.heatmap':
# Crear heatmap
sns.heatmap(
corr, xticklabels=boston.feature_names, yticklabels=boston.feature_names, cmap='coolwarm', annot=True, fmt='.2f',
cbar=False,
square=True,
annot_kws={'size': 7},
linewidth=.5,
)
plot.show()
En este ejemplo último, hemos desactivado a barra lateral con la escala de colores agregando 'cbar=False', establecer que los ejes sean iguales con 'square=True', modificar el tamaño de la fuente de los valores de correlación en las celdas con 'annot_kws= 7' y añadido espacio de separación entre celdas 'linewidth=.5'.
Con pequeñas modificaciones en el mapa de calor podemos mejorar mucho su legibilidad.
También podemos asignar el tamaño de la fuente a las etiquetas, en este caso indicando 'font_scale=1.5', pero dándole su tamaño antes de generar la imagen de la siguiente forma:
# Tamaño de la fuente
sns.set(font_scale=1.5)
# Crear heatmap (mapa de calor)
sns.heatmap(
corr, xticklabels=boston.feature_names, yticklabels=boston.feature_names, cmap='coolwarm', annot=True, fmt='.2f',
cbar=False,
square=True,
annot_kws={'size': 7},
linewidth=.5,
)
# Muestra el gráfico
plt.show()
Mapa de calor seleccionando columnas con pandas y Numpy
Hasta ahora hemos creado el mapa de color enviando todas las columnas de datos para su impresión, pero lo normal es que solo necesitemos visualizar en la imagen las columnas o variables deseadas. Para facilitar la tarea, también usamos la biblioteca pandas ya que nos va a facilitar mucho la obtención de las columnas o variables que deseamos utilizar. En ese caso, haríamos lo siguiente:
# -----------------------------------------------
# MAPA DE CALOR SOLO CON ALGUNAS COLUMNAS DEL DATAFRAME: usa pandas
# -----------------------------------------------
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.datasets import load_boston
# Carga el dataset Boston
boston = load_boston()
# Obtiene los datos de las variables
data = pd.DataFrame(boston.data, columns=boston.feature_names)
# Crea nueva columna 'MEDV' en el dataframe
data['MEDV'] = boston.target
# Selección de columnas a utilizar.
columnas = ['INDUS', 'RM', 'DIS', 'LSTAT', 'MEDV']
# Calcular matriz de correlación
corr = np.corrcoef(data[columnas].values.T)
#Tamaño de la fuente.
sns.set(font_scale=1.5)
# Crear heatmap
sns.heatmap(
corr, xticklabels=columnas, yticklabels=columnas, cmap='coolwarm', annot=True, fmt='.2f',
cbar=False,
square=True,
annot_kws={'size': 12},
linewidth=.5,
)
# Mostrar gráfico
plt.title('Diagrama de correlación', color='#E9785D')
plt.show()
# Convertir matriz Numpy a pandas DataFrame
corr = pd.DataFrame(corr, columns=columnas, index=columnas)
# Exportar datos a csv
path_output = 'correlaciones_corrcoef.csv'
corr.to_csv(path_output)
La diferencia en este ejemplo es el uso de pandas en lugar de solo utilizar una matriz NumPy. El uso de un DataFrame pandas facilita mucho el trabajo y reduce la complejidad a la hora de modificar y añadir columnas ya que con NumPy en muchas ocasiones es una tarea compleja, al menos mucho más que la facilidad que proporciona pandas.
El dataset lo asignamos a un DataFrame pandas, además, también añadimos una nueva columna llamada 'MEDV' como hicimos en los otros ejemplos de correlación de variables que hemos mencionado y enlazado, los ejemplos para descubrir relaciones con el método corr() de pandas y mostrarlas gráficamente con pairplot() de seaborn.
Asimismo, indicamos los nombres de las columnas en la variable llamada 'columnas' que vamos a obtener y que también nos sirve para añadir esos nombres en la cabecera del DataFrame y usarlo como índice cuando convertimos la matriz NumPy a un DataFrame pandas.
El cálculo del coeficiente de correlación lo realizamos de la misma forma, con el método numpy.corrcoef.
La generación del gráfico es igual, solo añadiendo el título, que es algo que en los otros ejemplos no habíamos añadido. El título lo añadimos con plt.title('Diagrama de correlación', color='#E9785D'), que es tono naranja.
Y para finalizar, también exportamos los datos a un archivo csv para poder disponer de ellos cuando los necesitemos.
Con esto, ya tendríamos 3 formas de mostrar las correlaciones en Python para poder analizar datos y usarlos de forma eficaz en nuestros modelos de Machine Learning y desarrollos de aprendizaje automático supervisado para hacer una mejor minería de datos de clientes y ofrecer una visión más completa de múltiples cuestiones sobre la evolución del negocio y posibles oportunidades que, a simple vista pueden resultar difíciles de encontrar.
Comentarios del artículo "Cómo crear un mapa de calor de correlaciones de datos en Python (corrcoef y heatmap)"
¿Te ha gustado la información? Coméntanos tus opiniones, dudas y sugerencias: