Cómo agrupar y resumir datos en Pandas
Pandas es una librería Python que se utiliza para el análisis y manipulación de datos. Una de las cosas que podemos hacer con esta biblioteca de código es agrupar y resumir datos. Usaremos el método 'groupby' que tiene diferentes posibilidades y formas de uso.
Una vez que tenemos los datos agrupados, podemos utilizar el método 'agg' para aplicar una o más funciones de agregación a los datos con la función 'mean' que calcula el promedio de una columna, o bien la función 'sum' para obtener la suma de los valores de esa columna.
A continuación, mostramos un ejemplo de cómo agrupar y resumir datos en Pandas:
En este ejemplo, primero cargamos los datos en un DataFrame de pandas utilizando el método 'read_csv', luego agrupamos los datos en función de la columna 'ciudad' utilizando el método 'groupby' y, finalmente aplicamos la función 'mean' a la columna 'temperatura' para calcular el promedio. El resultado se imprime por pantalla.
Es importante tener en cuenta que el método 'groupby' retorna un DataFrameGroupBy que no es un DataFrame pandas normal. Para obtener un DataFrame de pandas debemos aplicar una función de agreagación como la que se muetra en el ejemplo. Y esto es así de sencillo para agrupar y resumir datos en pandas. Con el método 'groypby' podemos unir datos según nuestras necesidades.
Además de groupby, pandas ofrece una serie de funciones y métodos para agrupar y resumir datos de diferentes maneras. Por ejemplo, con el método 'pivot_table' para crear una tabla de resumen de nuestros datos, o bien utilizar el método 'describe' para obtener estadísticas básicas de nuestros datos.
En cualquier caso, pandas es una biblioteca Python muy útil para el análisis y tratamientos de datos ya que su capacidad para agrupar y resumir permite obtener información valiosa a partir de grandes conjuntos de datos.
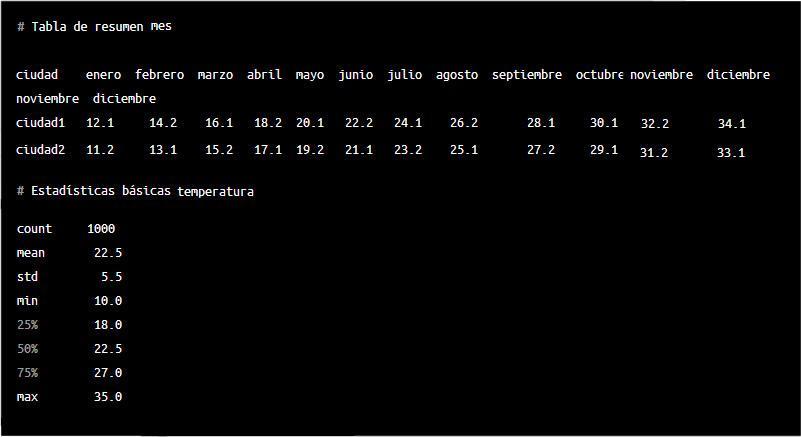
En el primer ejemplo, utilizamos el método 'pivot_table' para creaer una tabla de resumen que contiene el promedio de la temperatura en cada ciudad y mes. El ínidice de la tabla es la columna 'ciudad', la columna es 'mes' y los valores la columna 'temperatura', calculando el promedio de los valores mediante la función 'mean'. En el segundo ejemplo del script, utilizamos el método 'describe' para obtener estadísitcas básicas de nuestros datos. Este método realiza operación de forma sencilla como la media, la desviación estándar, el valor mínimo y máximo, entre otros.
En ambos casos, el resultado se imprime en pantalla para poder verlo. Es importante tener en cuenta que estos son solo algunos ejemplos de los métodos 'pivot_table' y 'describe' y que, los mismos pueden utilizarse de muchas maneras diferentes dependiendo de las necesidades del usuario.
El resultado que veríamos por pantalla sería similar al siguiente:
 Exportar el DataFrame después de agruparlo por columnas y realizar diversas operaciones con los datos es posible con una sola línea de código.
Exportar el DataFrame después de agruparlo por columnas y realizar diversas operaciones con los datos es posible con una sola línea de código.
NOTA: para poder usar el método 'to_excel' es necesario instalar antes la biblioteca 'openpyxl'. Si no la tenemos instalada nos dará error. Su instalación podemos reaelizarla con pip install openpyxl desde la consola de Python.
- Índice de contenidos:
Agrupar datos con pandas groupby
Para agrupar datos en Pandas, podemos utilizar el método 'groupby'. Este método nos permite agrupar los datos en función de una o más columnas, lo que nos permite realizar operaciones de agregación en los datos. Por ejemplo, podemos agrupar los datos en función de una columna que contenga el nombre de una ciudad y luego calcular el promedio de una columna que contenga la temperatura de esa ciudad, agrupar por clientes y calcular la media de ventas, etc.Una vez que tenemos los datos agrupados, podemos utilizar el método 'agg' para aplicar una o más funciones de agregación a los datos con la función 'mean' que calcula el promedio de una columna, o bien la función 'sum' para obtener la suma de los valores de esa columna.
A continuación, mostramos un ejemplo de cómo agrupar y resumir datos en Pandas:
import pandas as pd
# Cargamos los datos en un DataFrame de pandas
df = pd.read_csv('datos.csv')
# Agrupamos los datos en función de la columna 'ciudad'
df_group_city = df.groupby('ciudad')
# Aolicamos la función 'mean' a la columna 'temperatura' para calcular el promedio
df_resume = df_group_city['temperatura'].mean()
# Imprimos el resultado
print(df_resume)
Es importante tener en cuenta que el método 'groupby' retorna un DataFrameGroupBy que no es un DataFrame pandas normal. Para obtener un DataFrame de pandas debemos aplicar una función de agreagación como la que se muetra en el ejemplo. Y esto es así de sencillo para agrupar y resumir datos en pandas. Con el método 'groypby' podemos unir datos según nuestras necesidades.
Además de groupby, pandas ofrece una serie de funciones y métodos para agrupar y resumir datos de diferentes maneras. Por ejemplo, con el método 'pivot_table' para crear una tabla de resumen de nuestros datos, o bien utilizar el método 'describe' para obtener estadísticas básicas de nuestros datos.
En cualquier caso, pandas es una biblioteca Python muy útil para el análisis y tratamientos de datos ya que su capacidad para agrupar y resumir permite obtener información valiosa a partir de grandes conjuntos de datos.
Pandas pivot_table y describe
A continuación incluimos ejemplos de uso de los métodos 'pivot_table' y 'describe':
import pandas as pd
# Cargamos los datos en un DataFrame de pandas
df = pd.read_csv('datos.csv')
# Creamos una tabla de resumen utilizando el método pivot_table
df_resume = df.pivot_table(
index='ciudad',
columns='mes',
values='temperatura',
aggfunc='mean'
)
# Imprimios el resultado
print(df_resume)
# Obtenemos estadísticas básicas de nuestros datos utilizando el método 'describe'
df_statistics = df.describe()
# Imprimimos el resultado
print(df_statistics)
En ambos casos, el resultado se imprime en pantalla para poder verlo. Es importante tener en cuenta que estos son solo algunos ejemplos de los métodos 'pivot_table' y 'describe' y que, los mismos pueden utilizarse de muchas maneras diferentes dependiendo de las necesidades del usuario.
Explicación método 'describe'
El método 'describe' de panda retorna un DataFrame con el resultado de las estadístias básicas que calucla para los datos del DataFrame.El resultado que veríamos por pantalla sería similar al siguiente:
El resultado del método 'describe' nos muestra dos columnas: 'temperatura' y 'precipitación'.
Cada columna contiene diferentes estadísiticas para los datos de la columna correspondiente del DataFrame original.
Exportar el DataFrame con el conjunto de datos a Excel
Y si deseamos exportar el DtaFrame con el conjunto de datos a un archivo Excel, utilizaremos el méto 'to_excel' de la siguiente manera:
df_resume.to_excel('resumen.xlsx')
NOTA: para poder usar el método 'to_excel' es necesario instalar antes la biblioteca 'openpyxl'. Si no la tenemos instalada nos dará error. Su instalación podemos reaelizarla con pip install openpyxl desde la consola de Python.
Comentarios del artículo "Cómo agrupar y resumir datos en Pandas"
¿Te ha gustado la información? Coméntanos tus opiniones, dudas y sugerencias: